
■目次
・予測対象
・説明変数
・データソース
・分析手法
・モデルパラメータ
・モデル評価
・結果と比較
■予測対象
あるブログのある枠の収益予測を行う ※このブログサイトではないです
今回はBQMLでの予測とPythonでの予測を行いそれぞれの結果の比較も行う
1/1-4/31のデータでモデル作成、5/1-5/13のデータで予測する
⇒1年分あると季節性の特徴がわかる
■説明変数
日別で以下の説明変数を使用
・revenue数
・request数
・ユニークユーザ数
・月
・曜日
・クリック率
・視認率
■データソース
○BQMLで利用するデータ
広告実績レポートが入ったDBデータをGCPに移動して利用
データは日付ごとの収益やリクエスト数などが含まれている
○Pythonで利用するデータ
広告実績レポートのデータを直接参照
BQMLで分析している情報の計算フォーマットに合わせてPython側でも同条件でデータを取得
■分析手法
XGBoostを利用
XGboostとは?理論とPythonとRでの実践方法!|スタビジ
XGBoostの特徴
・精度が比較的高い
・学習に時間がかかる
・パラメータの数が多くチューニングが必要
■モデルパラメータ
基本のモデルパラメータを決めて、2パターンの分析で揃える
揃えるパラメータ
・ブースターパラメータ
・並列スレッド数
・決定木の深さの最大値
モデルパラメータ関連ページ
Python API Reference — xgboost 1.7.0-dev documentation
BQMLでは以下のようにモデルを作成
CREATE MODEL
product-〇〇.□□(※テーブル名)
OPTIONS(MODEL_TYPE = ‘BOOSTED_TREE_REGRESSOR’,
BOOSTER_TYPE = ‘GBTREE’,
NUM_PARALLEL_TREE = 3,
TREE_METHOD = ‘AUTO’,
COLSAMPLE_BYTREE = 1,
COLSAMPLE_BYLEVEL = 1,
COLSAMPLE_BYNODE = 1,
MAX_TREE_DEPTH = 6,
DATA_SPLIT_METHOD = ‘RANDOM’,
INPUT_LABEL_COLS=[‘target_val’]) AS
SELECT
ROUND(revenue/553585100,0) AS target_val,
ROUND(request/6706363100,0) AS request,
ROUND(uu/3122101100,0) AS uu,
EXTRACT(MONTH FROM t0.date) AS mon_num,
EXTRACT(DAYOFWEEK FROM t0.date) AS weekday_num,
EXTRACT(WEEK FROM t0.date) AS week_num,
ROUND(click/measurable_imps100,2) AS click_rate,
ROUND(viewable_imps/measurable_imps*100,0) AS view_rateFROM
t0product-〇〇.□□(※テーブル名)
WHERE t0.frame_id = 1
AND t0.label1 is null
AND DATE(t0.date) between ‘2021-01-01’ and ‘2021-04-30’;※処理を早くするために、値を小さくしている(revenue,request,uu)
1/1-1/7の平均値で割って小さくしている
Pythonでは以下のように指定
xgboost.XGBRegressor(booster=’gbtree’, nthread=3, max_depth = 6)
■モデル評価
モデルの評価値として今回、MAE,MSE,RMSE,R2、の4つの値を使用する
平均絶対誤差 MAE(Mean Absolute Error) :実際の値と予測値の絶対値を平均したものです
小さいほうがモデル精度がよい
平均二乗誤差 MSE(Mean Squared Error):平均化された誤差の値
小さいほうがモデル精度がよい
二乗平均平方根誤差 RMSE(Root Mean Squared Error):平均化された誤差の値。MSEよりも誤差が大きいほど過大に評価する
小さいほうがモデル精度がよい
決定係数 R²:推定された回帰式の当てはまりの良さ(度合い)を表す
1に近いほうがモデル精度がよい
■結果と比較
BQMLとPythonでの結果について比較する
・モデルに対する評価値の結果と比較
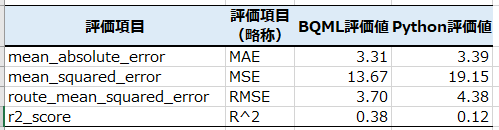
モデル評価は全体的にBQMLのほうが良い
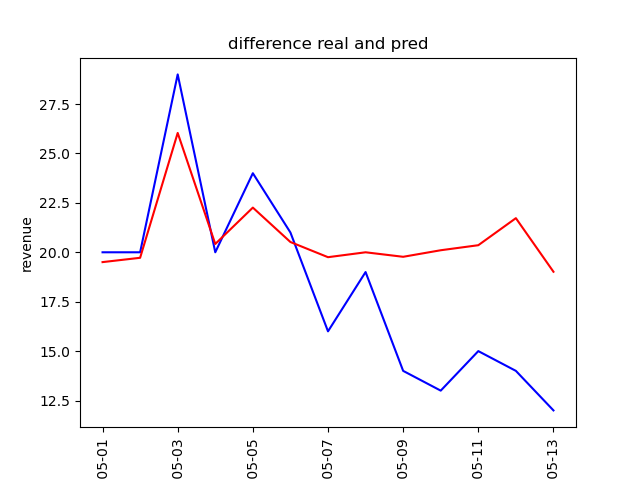
・収益予測結果についてPythonとBQMLとの比較
青色が実績、赤色が予測
Python
<5月1-13 予測>
BQML
<5月1-13 予測>
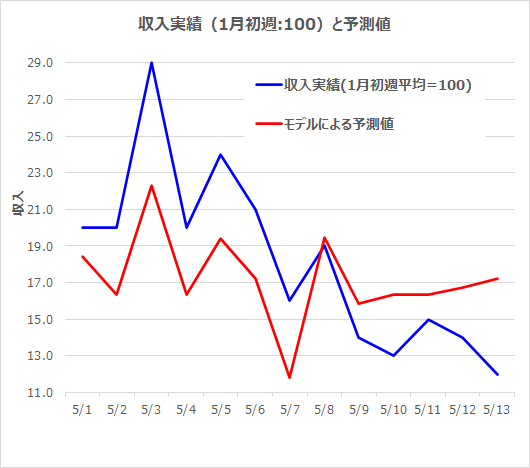
予測を見ても、BQMLのほうが精度が良い
パラメータ調整をしていないPythonを利用している一方、BQMLはよしなにパラメータを設定を設定してくれているので差がでていると思われる
機械学習に長けたエンジニアがいて、チューニングを手軽にできるのであればPython、
そうではない場合や属人化を避けるなど人手による手間を省きたい場合はBQML

コメント